
Escalamiento de profundidad con expansión de capas cero/uno
Descubre cómo la expansión de capas cero/uno acelera el entrenamiento hasta 5x y ahorra un 80% de cómputo sin perder rendimiento.
Descubre cómo la expansión de capas cero/uno acelera el entrenamiento hasta 5x y ahorra un 80% de cómputo sin perder rendimiento.

WUSH mejora la cuantización de LLMs hasta +2.8 puntos en W4A4. Transformaciones adaptativas casi óptimas para despliegue eficiente en GPU.

Descubre PaCoDi: difusión espectral para series temporales escalables. Supera a métodos tradicionales en calidad y eficiencia.

Flowers: arquitectura neuronal con warps multihead. Sin Fourier ni atención, logra interacciones globales a costo lineal. Supera a modelos mucho más grandes.
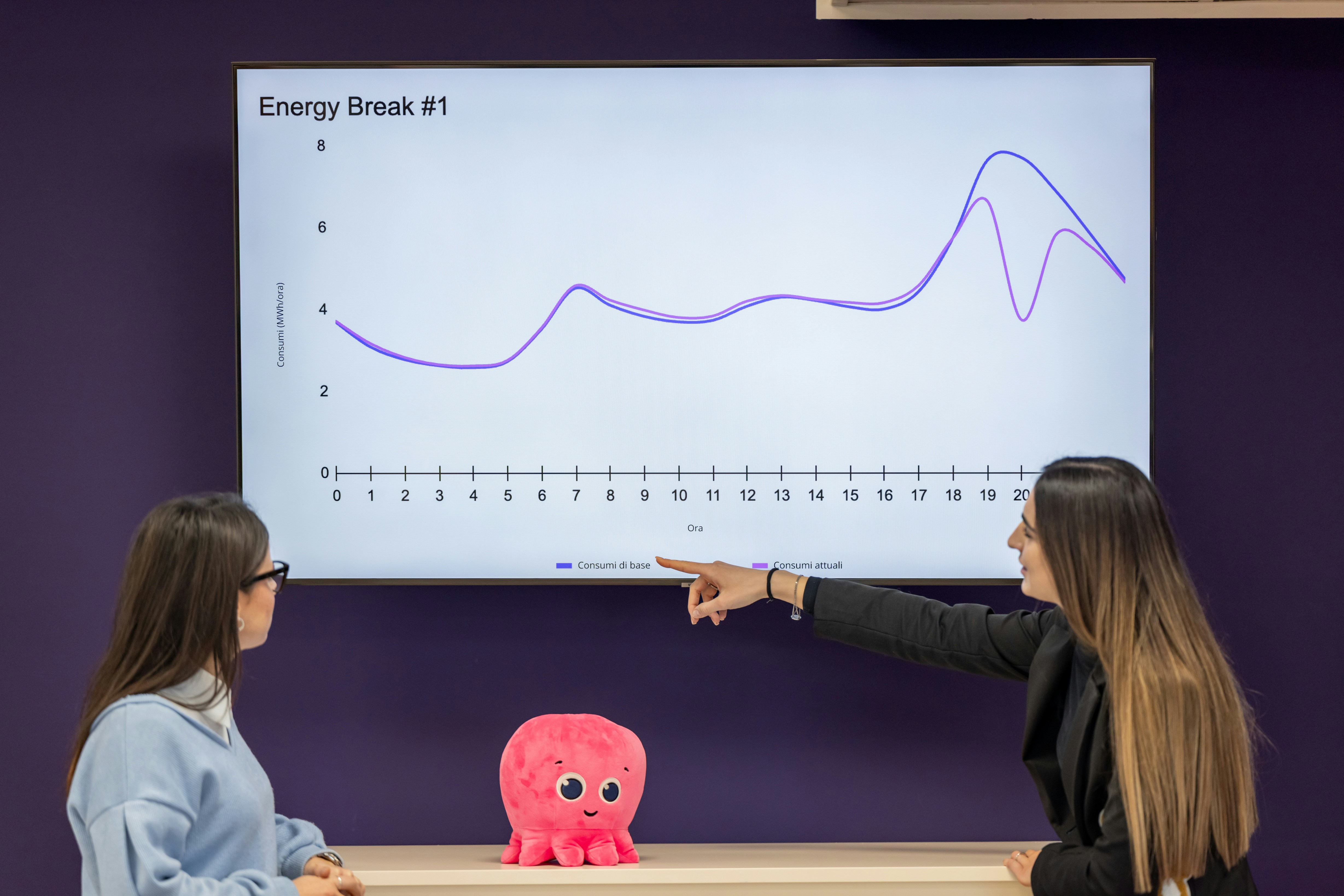
Descubre cómo MFPO acelera el entrenamiento e inferencia en aprendizaje por refuerzo superando limitaciones de modelos de difusión.

GUDA: atribución grupal contrafactual eficiente para modelos de difusión. Usa desaprendizaje y es 100x más rápido que reentrenar con cada grupo eliminado.

PiEvo revoluciona el descubrimiento científico al hacer evolucionar principios con IA. Logra un 31% más de calidad y un 83% de aceleración en la convergencia. Descúbrelo.

Descubre cuándo y cuánto imaginar en razonamiento espacial visual. AVIC optimiza el uso de modelos del mundo, superando a GPT-4o con menos recursos.

Descubre cómo LASER logra una aceleración 2.3x en modelos visión-lenguaje con baja precisión, usando SVD consciente de pérdida y asignación de rango.

Descubre cómo la Transformada de Fourier y las Series de Volterra mejoran los Procesos Neuronales, logrando campos receptivos globales y escalabilidad lineal en datos irregulares.

LookWise mejora el razonamiento visual detallado en modelos multimodales sin entrenamiento, logrando 4x más velocidad y mayor precisión en benchmarks. ¡Descúbrelo!

U-Cast, modelo probabilístico, entrena en 12 días y genera ensamble en 3 segundos, superando a GenCast e IFS con 10x menos cómputo.

Descubre cuánta ortogonalización necesita el optimizador Muon para entrenar redes neuronales de forma eficiente sin sacrificar precisión.

ProjQ revoluciona la compresión de LLMs al proyectar el ruido de cuantización en un subespacio de bajo rango. Obtén modelos más ligeros y eficientes con fine-tuning mejorado.
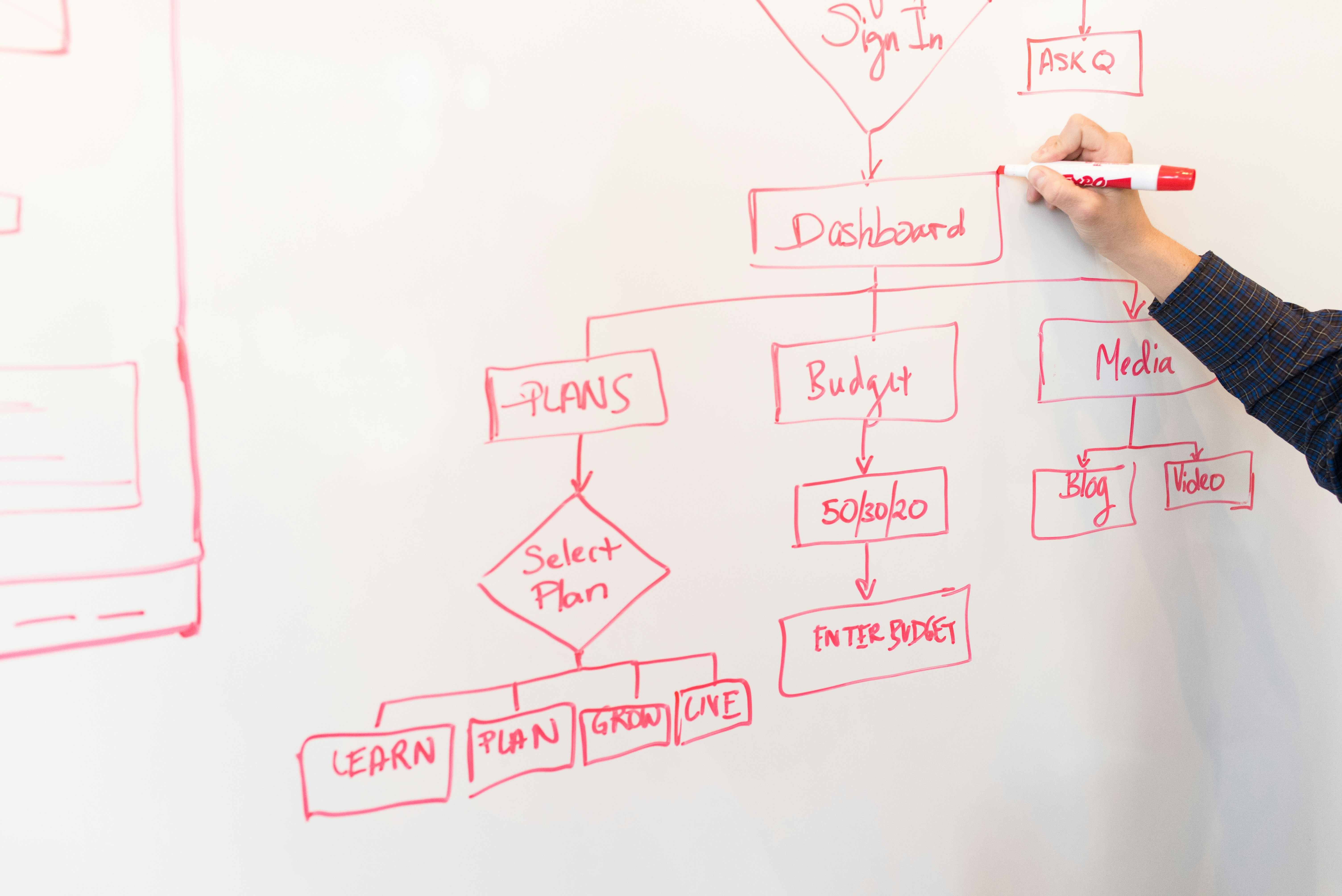
Optimiza la inferencia en tiempo de prueba con el algoritmo OCL, mejorando eficiencia y calidad de soluciones en planificación generativa.

Descubre cómo los conjuntos funcionales en redes neuronales espiga revelan patrones raros pero cruciales para el procesamiento de información en IA.

DLLM-JEPA: nueva arquitectura que combina JEPA y difusión enmascarada para reducir FLOPs un 33% y ganar hasta 18.7% en precisión.

¿Puede una IA optimizada como ChurnNet superar a los métodos clásicos de machine learning? Descubre los resultados en nuestra comparativa.

Optimiza el escalado de modelos dispersos con datos limitados. Descubre leyes de escalado, saturación retardada y compensaciones clave.

Descubre cómo el control de grupo adaptativo reduce los retrasos por rezagados en RL síncrono, acelerando el entrenamiento y mejorando el rendimiento en benchmarks.